Team 04 TORCS Racing Blog
Development blog for TORCS project.
Team Members:
- Jimi Wilson
- Kerem Nur
- Hannah Krebs Rocha
- Lewis Beamond
- Oliver Holbourns
- Rhys Womack
Week 3: The Big Rewrite
by Jimi
Code Review
We hit a major roadblock this week with the code review. After reviewing the codebase, we realised it was significantly outdated. It was written around 7 years ago and relied on deprecated libraries such as gym (which has since been replaced by gymnasium).
It was challenging to understand the code, so we turned to IBM Granite to help us analyse its functionality.
Granite’s analysis revealed that the code was originally designed for Linux and failed to implement a standard Gymnasium environment, which is crucial for our reinforcement learning (RL) approach.
Following this discovery, we made the decision to rewrite the code from scratch.
Research and Code Rewrite
Before attempting any rewrite, we needed to thoroughly understand TORCS and the SCR Patch.
During our initial research, we located the original competition for which the SCR patch was developed. Crucially, we found a supporting paper[1] that detailed how the patch interacts with the game, as well as the specific inputs and outputs at our disposal.
New Architecture
Equipped with a better understanding of both the original code and the SCR Patch, thanks to Granite, we designed a new architecture from the ground up.
To ensure a clean separation of concerns, we divided our system into distinct components that handle specific parts of the data flow, as shown in the diagram below.
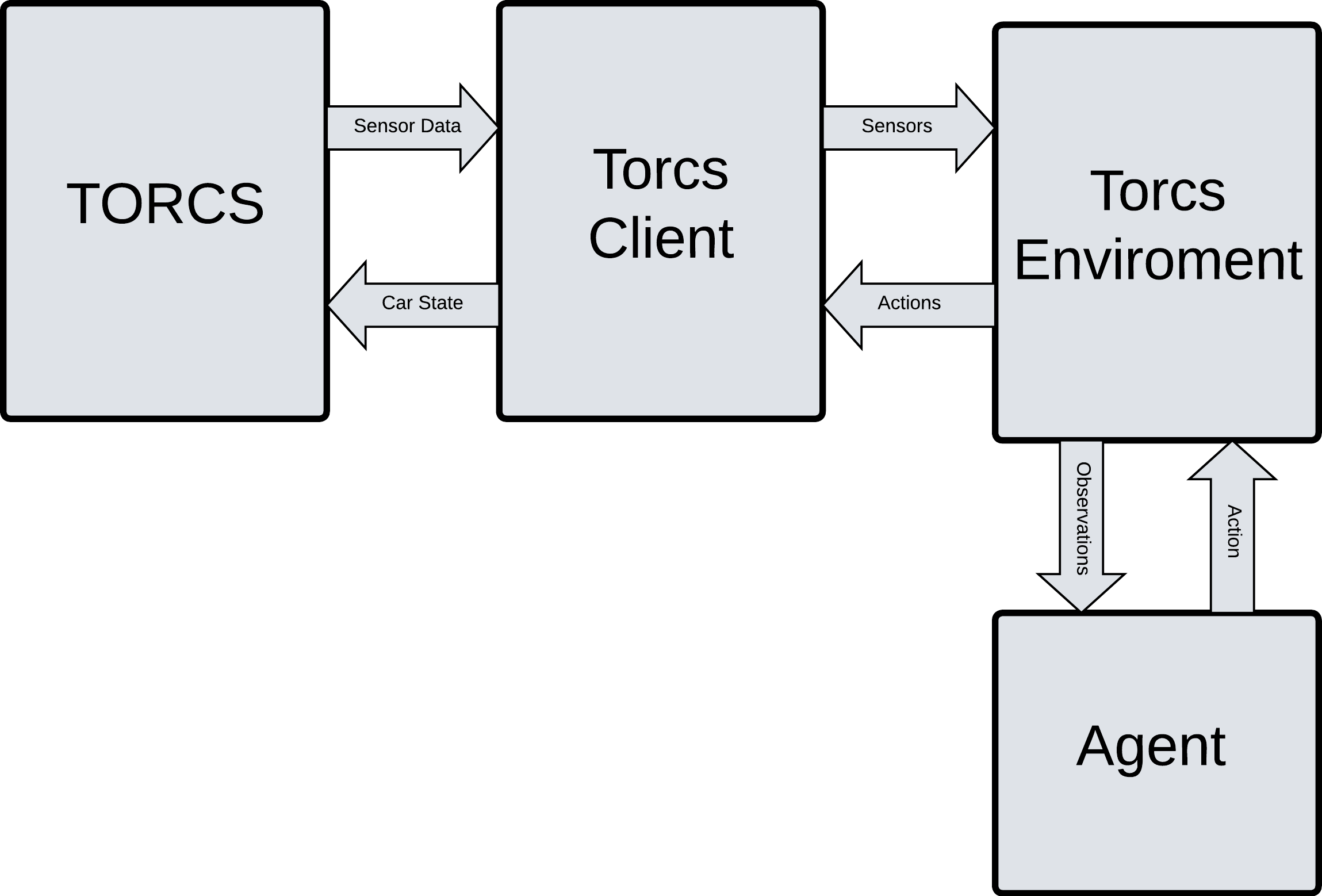
Torcs Client
The original Torcs Client was arguably the most cryptic component of the codebase, making IBM Granite and the Competition Manual invaluable resources during the rewrite.
Like the original, our version works by communicating with the TORCS Patch via UDP. It serves as the lowest-level bridge, extracting raw Sensor Data from the game and sending back the Car State.
Torcs Environment
This is our custom gymnasium wrapper. It acts as a translator between the client and our AI.
It pulls the raw Sensors from the Torcs Client and processes them into normalised Observations (e.g. track positioning, speed).
Conversely, it takes the Actions generated by the Agent and formats them properly before sending them back down to the client.
Agent
This is the “brain” of our reinforcement learning setup. At every timestep, the Agent receives the processes’ observations from the Environment, passes them through its neural network, and decides on the optimal Action (steering, acceleration, braking) to maximise its reward.
Implementation
Armed with this new architectural plan, we spent the remainder of the week successfully building the TorcsClient and TorcsEnv from scratch.
With the help of Granite, we stripped out the legacy Linux-specific OS commands and terminal UI bloat, replacing them with a streamlined, cross-platform UDP networking bridge and a modern, dynamic gymnasium environment.
Plans For Week 4
With the environment fully set up and communicating with the TORCS engine, our focus for next week shifts to developing an Agent and Reward Function.
[1]
tags: